- 标签
- 热门文章
- 推荐文章
Redis解析内存数据缓存解决方案
一、诞生背景与创始团队
Redis(Remote Dictionary Server)由意大利开发者Salvatore Sanfilippo于2009年创建。其诞生源于作者在实时Web日志分析项目LLOOGG中遇到的数据处理瓶颈。当时现有的数据库解决方案无法满足实时性和高性能需求,这促使Salvatore开发了一个基于内存的键值存储系统。
最初版本仅支持简单的字符串操作,但随着社区贡献和需求增长,Redis逐步发展成为功能丰富的数据结构服务器。2015年,Redis Labs公司成立,为Redis提供商业支持和企业级功能,进一步推动了Redis的广泛应用。
二、核心产品定位与价值
Redis本质上是一个开源的内存数据结构存储系统,可用作数据库、缓存和消息代理。其核心价值体现在四个方面:首先,提供亚毫秒级的数据访问速度,满足高性能应用需求;其次,支持丰富的数据结构,包括字符串、哈希、列表、集合等;再次,具备持久化能力,确保数据安全;最后,提供复制、事务、Lua脚本等高级功能。
三、关键技术特性详解
1. 内存存储架构:数据主要存储在内存中,实现极致的读写性能。
2. 丰富数据结构:支持字符串、列表、集合、有序集合、哈希、位图等数据结构。
3. 持久化机制:提供RDB快照和AOF日志两种持久化方案,确保数据安全。
4. 复制与高可用:支持主从复制,结合Sentinel实现自动故障转移。
5. 集群模式:通过分片技术实现水平扩展,支持大规模数据存储。
6. 原子操作:所有操作都是原子性的,支持事务和Lua脚本。
四、主流架构模式分析
Redis支持多种部署架构,每种架构都有其特定的应用场景和优势:
1.单机架构:最简单的部署方式,适用于开发和测试环境。优点是部署简单、维护成本低;缺点是存在单点故障风险,容量和性能受限于单台服务器。2.主从复制架构:通过主从复制实现数据冗余和读写分离。主节点处理写操作,从节点处理读操作,提升系统吞吐量。支持一主多从的拓扑结构,从节点可以级联复制。3.Sentinel哨兵架构:在主从复制基础上增加Sentinel进程,实现自动故障检测和故障转移。Sentinel集群通过投票机制选举新的主节点,确保系统高可用性。3.Cluster集群架构:分布式架构,将数据分片存储到多个节点。采用无中心节点的对等架构,每个节点保存部分数据和整个集群状态。支持自动数据分片和故障转移。
五、集群管理与高可用命令
集群状态检查:
# 查看集群节点信息redis-cli -h 127.0.0.1 -p 6379 cluster nodes# 检查集群状态redis-cli -h 127.0.0.1 -p 6379 cluster info# 查看集群槽位分配redis-cli -h 127.0.0.1 -p 6379 cluster slots
节点管理操作:
# 添加新节点到集群redis-cli --cluster add-node new_host:new_port existing_host:existing_port# 从集群中移除节点redis-cli --cluster del-node host:port node_id# 重新分片集群数据redis-cli --cluster reshard host:port --cluster-from node_id --cluster-to node_id --cluster-slots number --cluster-yes
故障转移管理:
# 手动执行故障转移redis-cli -h 127.0.0.1 -p 6379 cluster failover# 设置副本节点为只读模式redis-cli -h 127.0.0.1 -p 6380 replicaof host port# 监控主从复制状态redis-cli -h 127.0.0.1 -p 6379 info replication
六、集群稳健性保障机制
Redis集群的稳健性源于多重保障机制:首先,采用Gossip协议进行节点间通信,确保集群状态的一致性;其次,通过故障检测和自动故障转移机制,快速应对节点故障;再次,数据分片和副本机制确保数据的安全性和可用性;最后,客户端重定向机制使得在集群拓扑变化时,客户端能够自动连接到正确的节点。
七、集群槽位分配核心算法
Redis集群采用哈希槽(Hash Slot)分片机制,将整个键空间划分为16384个槽位。键的槽位计算使用CRC16算法:slot = CRC16(key) mod 16384。这种设计的优势在于:首先,槽位数量固定,便于管理和迁移;其次,哈希算法分布均匀,避免数据倾斜;最后,支持槽位的批量迁移,便于集群扩容和缩容操作。
八、集群扩容与缩容操作
集群扩容流程:
# 1. 准备新节点并启动Redis服务redis-server /path/to/redis.conf# 2. 将新节点加入集群redis-cli --cluster add-node new_host:new_port existing_host:existing_port# 3. 重新分配槽位redis-cli --cluster reshard host:port --cluster-from all --cluster-to new_node_id --cluster-slots 4096 --cluster-yes# 4. 添加副本节点(可选)redis-cli --cluster add-node replica_host:replica_port existing_host:existing_port --cluster-slave --cluster-master-id master_node_id
集群缩容流程:
# 1. 迁移待移除节点的槽位redis-cli --cluster reshard host:port --cluster-from node_id --cluster-to target_node_id --cluster-slots number --cluster-yes# 2. 确认所有槽位已迁移redis-cli -h host -p port cluster nodes# 3. 移除空节点redis-cli --cluster del-node host:port node_id
九、AOF与RDB持久化对比
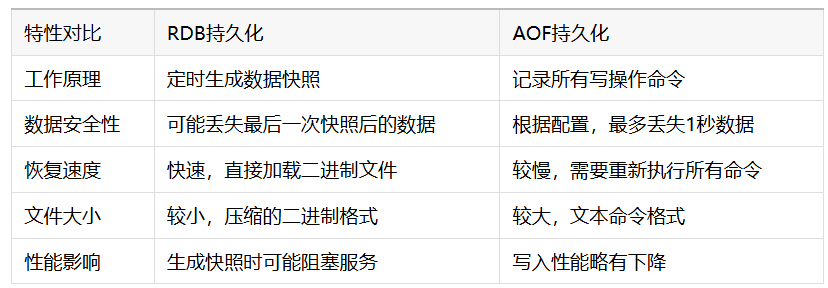
持久化配置命令:
# RDB配置save 900 1 # 900秒内至少1个键变化则保存save 300 10 # 300秒内至少10个键变化则保存save 60 10000 # 60秒内至少10000个键变化则保存# AOF配置appendonly yesappendfsync everysec # 每秒同步,平衡性能和数据安全# 混合持久化(Redis 4.0+)aof-use-rdb-preamble yes
十、大Key定位与优化技巧
大Key检测方法:
# 使用redis-cli大Key分析redis-cli --bigkeys# 内存分析工具redis-memory-analyzer.py# 自定义脚本扫描redis-cli -h host -p port --scan --pattern '*' | while read key; doecho "Key: $key, Size: $(redis-cli -h host -p port memory usage $key)"done | sort -k4 -nr | head -20
大Key优化策略:首先,对大Value进行拆分,将单个大Key拆分为多个小Key;其次,使用压缩算法减少数据体积;再次,对于集合类型,考虑分片存储;最后,定期清理过期数据和优化数据结构选择。
十一、慢查询分析与优化
慢查询配置与监控:
# 设置慢查询阈值(微秒)config set slowlog-log-slower-than 10000# 设置慢查询日志最大长度config set slowlog-max-len 128# 查看慢查询日志slowlog get 10# 清空慢查询日志slowlog reset
慢查询优化方案:首先,避免使用复杂度为O(N)的命令处理大数据集;其次,使用批量操作减少网络往返;再次,合理使用管道和事务;最后,对热点数据增加本地缓存,减少Redis访问频率。
十二、核心监控指标体系
1. 内存使用率:监控used_memory、used_memory_rss、mem_fragmentation_ratio等指标。2. 连接数统计:关注connected_clients、blocked_clients、rejected_connections等。3. 命令统计:分析命令调用频率和耗时,识别性能瓶颈。4. 持久化状态:监控rdb_last_save_time、aof_current_size、aof_delayed_fsync等。5. 复制状态:关注master_link_status、master_last_io_seconds_ago等指标。6. 键空间统计:跟踪keyspace_hits、keyspace_misses等缓存命中率指标。
十三、关键性能优化参数
# 内存优化maxmemory 16gbmaxmemory-policy allkeys-lru# 网络优化tcp-keepalive 60timeout 300# 持久化优化stop-writes-on-bgsave-error nordbcompression yesrdbchecksum yes# 客户端优化maxclients 10000client-output-buffer-limit normal 0 0 0
十四、高并发处理机制
Redis实现高并发处理的核心机制包括:首先,单线程事件循环模型避免了上下文切换和锁竞争;其次,I/O多路复用技术(epoll/kqueue)高效处理大量并发连接;再次,内存操作消除了磁盘I/O瓶颈;最后,通过管道技术批量处理命令,减少网络往返开销。
在实际应用中,通过以下策略支持万级并发:合理配置连接池参数,避免频繁创建连接;使用连接复用和管道技术;对热点数据采用本地缓存;通过集群分片分散请求压力;优化数据结构和使用Lua脚本减少网络交互。
十五、最新版本功能特性
Redis 7.0版本引入了多项重要改进:首先,支持函数计算(Redis Functions),提供更强大的服务器端脚本能力;其次,优化了ACL权限控制系统,提供更细粒度的访问控制;再次,改进了集群管理功能,提升了故障转移的可靠性;最后,增强了性能监控能力,提供了更详细的运行时指标。
Redis 7.2版本进一步强化了企业级特性:改进了内存管理和碎片整理算法;增强了多线程I/O性能;提供了更好的TLS/SSL支持;优化了流数据处理能力,为实时分析场景提供更好支持。
十六、未来发展趋势展望
Redis的未来发展将聚焦于四个方向:在架构层面,继续优化多线程模型,平衡性能与复杂度;在功能层面,增强流处理和时序数据处理能力;在生态层面,深化与云原生技术的集成,提供更好的Kubernetes支持;在应用层面,拓展在AI/ML、边缘计算等新兴场景的应用。
随着实时数据处理需求的持续增长,Redis将继续在缓存、会话存储、消息队列等传统场景发挥核心作用,同时在实时推荐、物联网数据处理、金融风控等新兴领域拓展应用边界。预计未来版本将进一步强化数据安全、运维便捷性和性能表现,满足企业级应用的严苛要求。
上一条:购软平台是redis厂商
下一条:Redis一个强大的内存数据库




 沪公网安备31011302006932号
沪公网安备31011302006932号