- 标签
- 热门文章
- 推荐文章
Redis如何解决缓存穿透
高并发缓存穿透
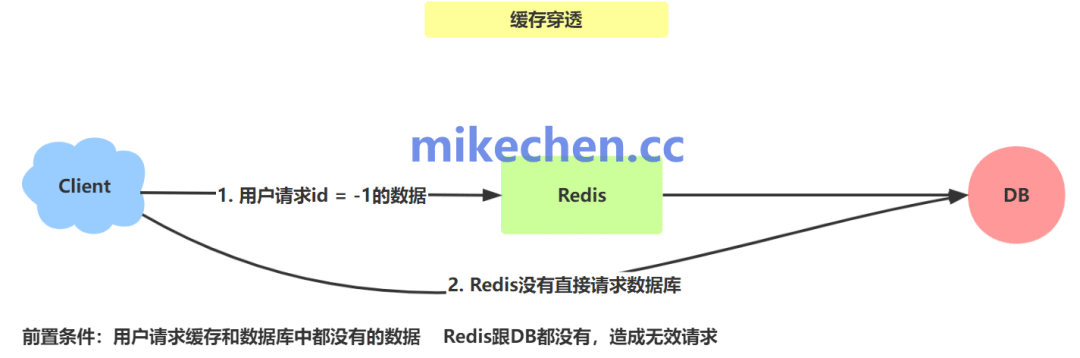
缓存穿透,是高并发系统中,一种常见的性能瓶颈问题。
它指的是用户查询的数据在缓存中不存在(缓存miss),同时在后端数据源(如数据库)中也不存在。
导致每次查询都直接“穿透”缓存层,直达数据源进行无效查询。
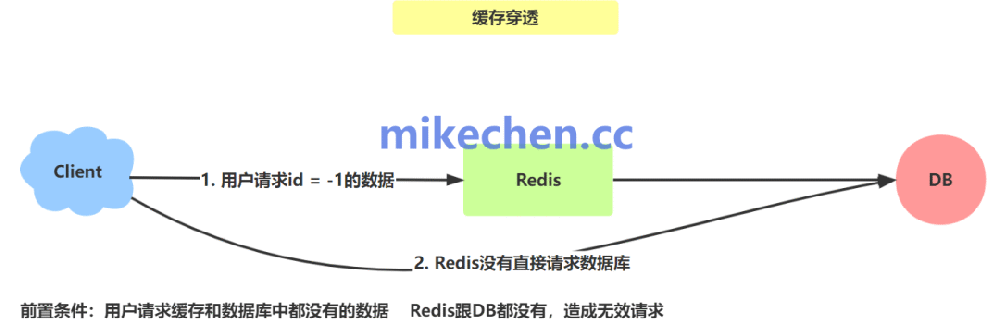
如果这种查询是高频或恶意发起的,会造成数据源的无效负载急剧增加,甚至耗尽资源,导致系统响应变慢或崩溃。
为什么会发生缓存穿透
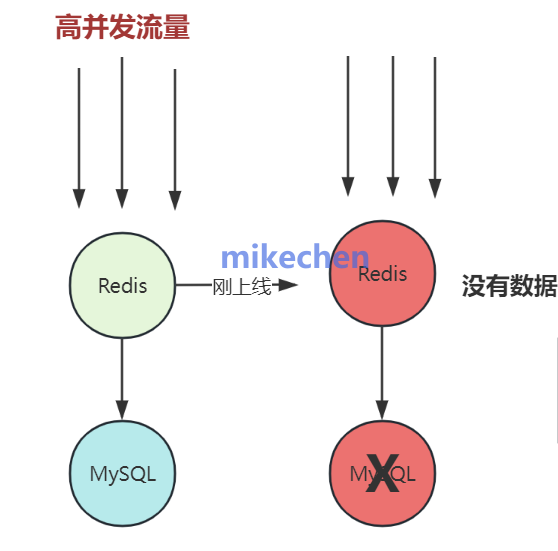
缓存穿透的发生,通常源于数据不存在的查询模式与系统设计的交互,这些因素在高并发或开放API环境中易被放大。
主要原因包括:恶意攻击:攻击者使用不存在的键。
如随机生成的负ID或超大ID,高频查询,绕过缓存直接打击DB,常见于DDoS变种或爬虫攻击。
数据未加载:业务逻辑中,新数据尚未写入DB。
或历史数据被删除后缓存未及时清理,导致合法查询也穿透。
查询参数异常:用户输入无效参数(如空字符串、非法格式)。
或接口未做参数校验,直接转发到缓存/DB。
缓存穿透的四大解决方案
方案一:缓存空值(Cache Empty Value)或默认值
核心思想: 将数据库中不存在的 Key 也在缓存中存一个标记。
具体做法: 当应用层从缓存未命中并查询数据库后,如果数据库返回的结果是空。
则将这个 Key 和一个空值(例如:null、"-1" 或一个特定的占位符)一同写入缓存。
优势: 简单易实现,能有效拦截大部分无效查询。
缺点: 1. 缓存需要存储额外的空 Key,占用存储空间;2. 需要设置合理的过期时间,防止短期内新增的数据无法被查到。
方案二:布隆过滤器(Bloom Filter)
核心思想: 在缓存之前增加一层快速识别机制,判断 Key 是否"可能存在"。
具体做法:
将所有可能存在的 Key(例如所有的用户 ID)的哈希值映射到一个巨大的 位图(BitMap) 中。
当请求到达时,先用布隆过滤器判断 Key 是否存在。
如果布隆过滤器判断 Key 肯定不存在: 直接返回,请求被拦截。
如果布隆过滤器判断 Key 可能存在: 才允许其进入缓存层和数据库层查询。
优势: 空间效率和时间效率极高,对恶意的大量无效查询有极强的拦截能力。
缺点: 存在误判率(False Positive),即布隆过滤器可能误判一个不存在的 Key 为存在。
虽然误判率很低,但会导致少量无效请求穿透到数据库。
方案三:数据合法性校验
核心思想: 在进入缓存层之前,检查请求参数是否符合业务规范。
具体做法: 在应用服务层或 API 网关层,对查询参数(如用户 ID、商品 ID、订单号等)进行严格的格式和范围校验。
格式校验: 检查 ID 是否为正整数、是否符合 UUID 格式等。
优势: 简单有效,可以直接在请求入口处拦截不合法的攻击。
缺点: 只能拦截格式不正确或超出业务范围的 Key,无法拦截格式正确但数据库中不存在的 Key。
方案四:请求层限流与风控
核心思想: 限制特定 IP 或用户的请求频率,应对恶意攻击。
优势: 可以针对恶意攻击源头进行防御,是系统级别的安全兜底措施。
缺点: 实现相对复杂,需要实时监控和分析用户行为。
下一条:Redis高可用实现方式详解




 沪公网安备31011302006932号
沪公网安备31011302006932号