- 标签
- 热门文章
- 推荐文章
GraphPad Prism 描述性统计
操作方法:描述性统计
GraphPadPrism
为描述性统计录入数据
按列进行的描述性统计最常与以“列数据”格式录入到数据表中的数据配合使用。如果想尝试操作,可以创建一个列数据表,然后选择示例数据集:单向方差分析(One-wayANOVA),常规型。
也可以从录入到XY数据表或分组(Grouped)数据表中的数据里选择描述性统计分析。
选择描述性统计分析
点击“分析(Analyze)”按钮,从列数据的分析列表中选择描述性统计(Descriptivestatistics)。
Prism的描述性统计分析会计算每个数据集的描述性统计量。正态性检验以及检验某一列的均值是否与假设值存在差异是单独的分析。
选择分析选项
基础
四分位数(quartiles)、中位数(median)、标准差(SD)和标准误(SEM)。
高级
变异系数(coefficientofvariation)、偏度和峰度(skewnessandkurtosis)、几何均值(geometricmean)、调和均值(harmonicmean)和二次均值(quadraticmean)。
置信区间
选择报告均值、几何均值或中位数的置信区间(CI)。
子列
当分析以列数据格式录入到表格(无“子列”)中的数据时,“子列”相关选项不可用。如果您的数据为XY或分组数据(含“子列”)格式化的表格中,可选择为每个“子列”单独计算列统计量,或者对“子列”取平均后计算基于均值的列统计量。
如果数据表有用于录入均值和标准差或标准误值的“子列”,Prism会针对均值计算列统计量,且会忽略录入时的标准差或标准误值。
分析检查清单:描述性统计
结果解读:四分位数与四分位距
GraphPadPrism
什么是百分位数?
百分位数有助于体现个体在群体中的相对位置。百分位数本质上是标准化的秩次。第80百分位数是这样一个数值,在该数值处,80%的值更低,20%的值更高。百分位数与数据的单位相同。
中位数
中位数是第50百分位数。一半的值更高,一半的值更低。将数值按从低到高排序。如果数据点个数为奇数,中位数就是中间的那个值。如果数据点个数为偶数,中位数是中间两个值的平均值。
四分位数
四分位数将数据分为四组,每组包含数量相等的值。四分位数由第25、第50和第75百分位数划分,也被称为第一、第二和第三四分位数。四分之一的值小于或等于第25百分位数。四分之三的值小于或等于第75百分位数。
四分位距
第75百分位数与第25百分位数的差值称为四分位距。它是量化离散程度的一种有效方式。
计算百分位数
计算中位数以外的百分位数并非易事,至少有八种不同的计算百分位数的方法。这里有对不同方法的另一种解释。
Prism计算百分位数值时,首先计算以下表达式:
R=P*(n+1)/100
其中,P是所需的百分位数(对于四分位数,P为25或75),n是数据集中值的数量。计算结果是与该百分位数值对应的秩次。如果有68个值,第25百分位数对应的秩次为:
0.25*69=17.25
Prism在第17个和第18个值之间进行四分之一距离的插值。这是统计程序中最常用的方法。它属于Hyndman和Fan中的定义6。通过这种方法,任意一点的百分位数为k/(n+1),其中k是秩次(从1开始),n是样本量。Excel计算百分位数的方式与此不同,因此当样本量较小时,Prism和Excel计算出的百分位数不匹配。
注意小数据集的百分位数。考虑这样一个例子:六个值的第90百分位数是多少?使用上面的公式,R等于6.3。由于最大值的秩次为6,实际上无法计算第90百分位数。Prism将最大值报告为第90百分位数。类似的问题也会出现在尝试计算六个值的第10百分位数时。R等于0.7,但最小值的秩次为1。Prism将最小值报告为第10百分位数。
需要注意的是,计算中位数的方法没有歧义。所有百分位数的定义对于中位数都会得出相同的结果。
五数概括
“五数概括“这一术语用于描述五个值的列表:最小值、第25百分位数、中位数、第75百分位数和最大值。这些值与箱线图(当须延伸至最小值和最大值时)中绘制的值相同;Prism还提供了其他定义须的方式。
结果解读:均值、标准差(SD)、均值标准误(SEM)
GraphPadPrism
均值
均值即平均值。将数值相加再除以数值的个数。
标准差
标准差(SD)用于量化变异性。它的单位与数据的单位相同,常缩写为“s”。Prism计算标准差时使用的分母是n-1,因此计算的是有时被称为“样本标准差”而非“总体标准差”的值。
均值标准误与均值的置信区间
均值标准误(SEM)用于量化均值的精确性,是对样本均值与真实总体均值之间可能存在的偏差的一种度量,其单位与数据的单位相同。
均值标准误用于计算均值的置信区间,该置信区间更易于解读。如果数据是从高斯分布中抽样得到的,您可以有95%的把握确定该区间包含总体均值。
方差
方差等于标准差的平方,因此其单位是数据单位的平方。数学家倾向于研究方差,因为他们可以将方差分解为不同的组成部分,这是方差分析(ANOVA)的基础。相比之下,将标准差分解为组成部分是不正确的。由于方差的单位通常难以理解,大多数科学家不会报告数据的方差,而是使用标准差。Prism不报告方差。
结果解读:中位数及其置信区间(CI)
GraphPadPrism
中位数是第50百分位数。一半的值大于(或等于)中位数,另一半的值小于中位数。
中位数的置信区间是通过一种标准方法计算的,该方法在Zar的著作中有详细阐述,基于二项分布。
四点说明:
中位数的置信区间并非围绕中位数对称分布
在解读置信区间时,无需假设总体分布是对称的
置信区间的起止值均为数据集中的数值,无需插值
即便您要求的是95%的置信水平,实际置信水平通常也会不同(尤其是在小样本情况下),Prism会报告实际置信水平
结果解读:变异系数
GraphPadPrism
变异系数(CV),也被称为“相对变异性”,等于标准差除以均值。它可以用分数或百分数来表示。
报告变异系数有什么优势?唯一的优势是它能让您比较以下不同单位表示的变量的离散程度。比较血压的标准差和脉搏率的标准差是没有意义的,但比较两者的变异系数可能是有意义的。
说明:
只有对于像质量或酶活性这类变量,报告变异系数才有意义,在这些变量中,“0.0”被明确地定义为真正的零。体重为零意味着没有重量,酶活性为零意味着没有酶活性,这些被称为比率变量。将比率变量(如体重或酶活性…)的变异性用变异系数来表示会很有帮助。相反,“0.0”摄氏度并不意味着零温度(除非用开尔文温度来测量),所以报告以摄氏度表示的值的变异系数是没有意义的
计算以对数形式表示的变量的变异系数是完全没有意义的,因为零的定义是任意的。1的对数等于0,所以当实际值等于1时,对数就等于0。通过改变单位,您会在原始尺度上重新定义1.0,从而在对数尺度上重新定义零,进而重新定义变异系数。因此,对数的变异系数时没有意义的。pH时对数尺度上测量的(它时氢离子浓度的负对数)。pH为0.0并不意味着“没有pH”,当然也不意味着“没有酸性”(恰恰相反)。因此,计算pH的变异系数时没有意义的
在计算变异系数时,Prism计算的标准差是样本标准差(使用n-1作为分母),而不是总体标准差(使用n作为分母)。
结果解读:几何均值及其置信区间(CI)
GraphPadPrism
Prism如何计算几何均值?
计算所有值的对数,计算对数的均值,然后取反对数。Prism使用以10为底(常用)的对数,然后将10取对数均值的幂来得到几何均值。这等同于将所有值相乘,然后将该乘积取1/n的次幂,其中n是值的数量。
几何均值常被用于对比例进行平均。
当数据的对数几何形成对称的近似高斯分布时,使用几何均值是有意义的。
Prism如何计算几何标准差(SD)?
首先,将所有值转换为对数,计算这些对数值的样本标准差,然后取该标准差的反对数。Prism使用以10为底(常用)的对数,然后将10取对数均值的幂来得到几何均值。
几何标准差因子没有单位,是一个无量纲的比率。
将几何标准差与几何均值(或任何其他值)相加是没有意义的,同样,从几何均值中减去几何标准差也没有意义。几何标准差是一个您始终要与之相乘或相除的值。如果数据是从对数正态分布中抽样得到的,那么从(几何均值除以几何标准差因子)到(几何均值乘以几何标准差因子)的范围将包含大约三分之二的值。类似地,当数据是从高斯分布中抽样得到的,从(均值减去标准差)到(均值加上标准差)的范围将包含大约三分之二的值。
如何报告几何均值和标准差?
虽然常见的是将从高斯分布中抽样的数据报告为“均值为3.2±1.2(SD)”,但目前很少将从对数正态分布中抽样的数据报告为“几何均值为4.3*÷1.14”。但这种报告方式是有意义的。在报告从对数正态分布中抽样的数据的结果时,不要使用对从高斯分布中抽样的数据有意义的“加减”符号,而应使用表示“乘以或除以”的符号。
示例
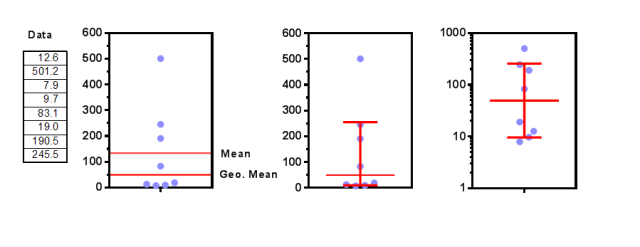
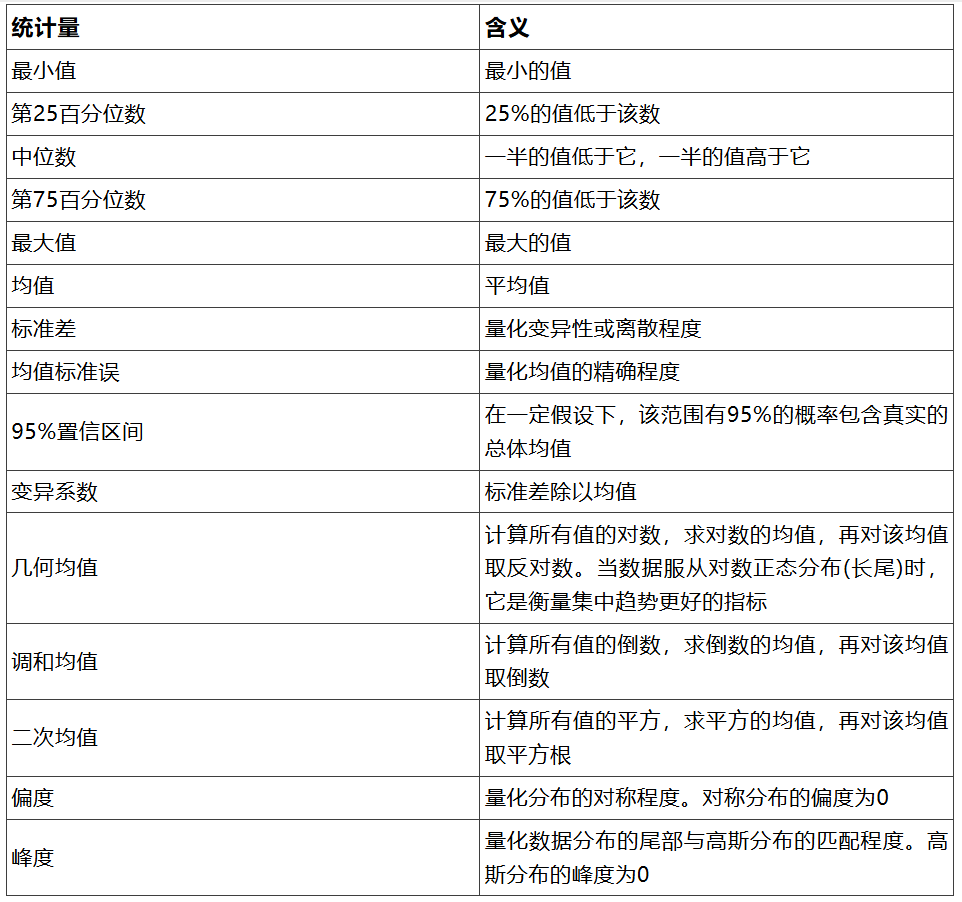
上述示例展示了八个数值(若愿意,可自行进行计算)。几何均值为49.55,几何标准差(SD)系数为5.15。左侧图表展示了带有标注均数和几何均数直线的数据。中间图表展示了GraphPadPrism软件如何绘制几何均数和几何标准差。上方误差线延伸至几何均数乘以几何标准差系数(49.55×5.15=255.2)处。下方误差线延伸至几何均数除以几何标准差系数(49.55÷5.15=9.62)处。右侧图表展示了在对数轴上绘制的数据、几何均数以及几何标准差。对数标准差误差线在对数轴上视觉上呈现对称,尽管从数值上看它们极不对称。
结果解读:偏度
GraphPadPrism
偏度的关键要点
偏度用于量化分布的对称程度。
对称分布的偏度为零
长尾朝右(数值较大方向)的非对称分布呈正偏态
长尾朝左(数值较小方向)的非对称分布呈负偏态
偏度是无量纲的
任何阈值或经验法则都是人为设定的,但有一个参考:若偏度大于1.0(或小于-1.0),则偏度较为显著,分布远非对称
偏度的计算方式
偏度有多种定义方式。以下步骤解释了GraphPadPrism所用的方式(称为G1,是最常用的方法之一),它与Excel种的skew()函数一致。
我们想要了解围绕样本均值的对称性。所以第一步是用每个数值减去样本均值。结果对于大于均值的数值为正,对于小于均值的数值为负,对于恰好等于均值的数值为零
为了计算无量纲的偏度度量,将步骤1种计算出的每个差值除以这些数值的标准差(需要注意的是,在计算偏度时,应使用N而不是N-1来计算标准差)。这些比率(每个数值与均值的差值除以标准差)被称为z分数
对每个数值,计算z3。需要注意的是,对数值进行立方运算会保留符号。正值的立方仍然为正,负值的立方仍然为负
计算z3值的平均值(计算所有z3值的总和,然后将该总和除以样本中的数值个数)。如果分布是对称的,正值和负值会相互抵消,平均值将接近零。如果分布不对称,若分布向右偏斜,平均值为正:若分布向左偏斜,平均值为负。这个平均值被称为费希尔-皮尔逊偏度系数,有时也记为“g1”
偏差校正:步骤4中计算出的平均值在小样本时存在偏差,其绝对值比实际应有的值小。通过将z3的均值乘以比率√(N*(N-1))/(N-2)来校正偏差。如果偏度为正,这种校正会增大该值;如果偏度为负,这种校正会减小该值。随着N变得更大,这种校正会更接近1,从而校正作用减弱。但对于小样本且偏度更显著的情况,校正作用更强。最终校正后的值有时被称为“调整后的费希尔-皮尔逊偏度系数”,有时记为“G1”。这就是Prism报告的偏度值
Prism报告的偏度值的完整公式为:
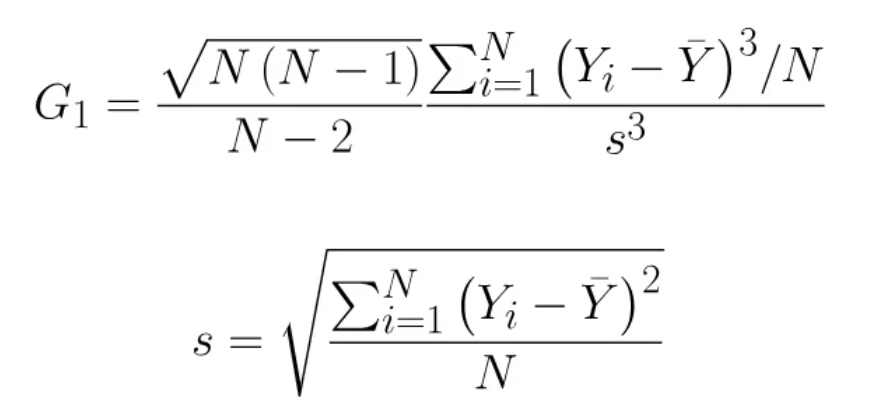
结果解读:峰度
GraphPadPrism
峰度
峰度用于量化数据分布的尾部与高斯分布(正态分布)的匹配程度。
高斯分布的峰度为0
尾部数值比高斯分布少的分布,峰度为负
尾部数值比高斯分布多(或尾部数值更靠外)的分布,峰度为正
峰度无单位
尽管人们通常认为峰度是衡量峰值形状的指标,但实际上峰度几乎无法告诉您峰值的形状。它唯一明确的解释是关于尾部数值的情况。从本质上讲,它衡量了异常值的存在情况
Prism报告的值有时被称为超额峰度(excesskurtosis),因为高斯分布的预期峰度为0.0
峰度的另一种定义是在Prism报告的值基础上加3。按照这种定义,高斯分布的预期峰度为3.0
峰度的计算方法
用每个数值减去样本均值。结果中,大于均值的数值为正,小于均值的数值为负,恰好等于均值的数值为零
将步骤1中计算得到的每个差值除以这些数值的标准差。这些比率(每个数值与均值的差值除以标准差)被称为z比率。根据定义,这些值的平均值为0,且它们的标准差为1
对每个数值,计算z4(即z的四次方)。若该表达式显示不清晰,特此说明,是z的四次方。所有这些值均为正数
对这组数值求平均值,将这些数值的综合除以n-1(其中n是样本中的数值个数)。为什么用n-1而不是n?原因与计算标准差时使用n-1的原因相同
对于高斯分布,您预期这个平均值等于3。因此,从该平均值中减去3。高斯数据的预期峰度为0。这个(减去3之后的)值有时被称为超额峰度
为什么分布中间的数值对峰度影响不大?
因为z值被取四次方,只有大的z值(即只有远离均值的数值)才会对峰度产生较大影响。如果一个数值的z值为1,另一个的z值为2,那么第二个数值对峰度的影响会是前者的16倍(因为2的四次方是16)。如果一个数值的z值为1,另一个的z值为3(即距离均值的距离是前者的三倍),那么第二个数值对峰度的影响是前者的81倍(因为3的四次方是81)。相应地,靠近均值的数值(尤其是那些距离均值小于1个标准差的数值)对峰度的影响非常小,而远离均值的数值则有巨大影响。因此,峰度并非量化峰值的陡峭程度,也并非真正量化分布主体部分的形状。相反,峰度量化的是远离均值的点的整体影响。
调和平均数、二次平均数、截尾平均数和缩尾平均数
GraphPadPrism
调和平均数
Prism计算调和平均数及其置信区间时,首先将所有数值转换为它们的倒数,然后计算这些倒数的平均数以及该平均数的置信区间(CI)。调和平均数就是这个平均数的倒数。如果数值均为正数,较大的数实际上比较小的数得到的权重更小。调和平均数最常用于求一组比率或速度的平均值。
当数据的倒数集合形成对称的、近似高斯的分布时,使用调和平均数是合理的。
二次平均数
Prism计算二次平均数及其置信区间时,首先将所有数值转换为它们的平方(数值乘以自身),然后计算这些平方值的平均数以及该平均数的置信区间。二次平均数是这个平均数的平方根。二次平均数也被称为均方根。
当数据的平方集合形成对称的、近似高斯的分布时,使用二次平均数是合理的。
截尾平均数和缩尾平均数
截尾或缩尾平均数的思路是不让最大和最小的数值产生太大影响。在计算截尾或缩尾平均数之前,首先得选择要忽略或降低权重的最大和最小数值的数量。如果将K设为1,最大和最小的数值会被区别对待。如果将K设为2,那么两个最大和两个最小的数值会被区别对待。K必须提前设定。有时K被设为1,其他时候被设为数值数量的某个小部分,所以当有大量数据时,K会更大。
要计算截尾平均数,只需删除K个最小和K个最大的观测值,然后计算剩余数据的平均数。
要计算缩尾平均数,用第K+1位的数值替换K个最小的数值,用第N-K-1位的数值替换K个最大的数值,然后计算数据的平均数。
截尾和缩尾平均数的优点是它们不受一个(或几个)非常高或非常低的数值的影响。Prism不计算这些数值。
众数
众数是出现次数最多的数值。对于以至少几位有效数字精度评估的测量值,众数没什么用处,因为大多数数值都是唯一的。对于只能取整数值的变量,众数可能有用。虽然众数常被列入这类统计量列表中,但它并不总是能衡量分布的中心。想象一项医学调查,其中有一个问题是“你做过多少次手术”?在很多人群中,最常见的答案是零,所以零就是众数。在这种情况下,这些数值会高于众数,但没有低于众数的,所以众数并非衡量分布中心的方式。
上一条:Docusign Navigator AI 自定义提取掌控关键合同数据
下一条:SnapGene v8.2 更新




 沪公网安备31011302006932号
沪公网安备31011302006932号